부트캠프에서 진행한 2주 기간의 온프레미스 프로젝트 개요
문제점
기존 3-tier 아키텍처의 한계
초기 아키텍처를 일반적인 3-tier 아키텍처라고 생각했을 때
- Web / WAS / DB 계층으로 구성
- 애플리케이션 서버가 직접 DB와 캐시, 백그라운드 처리까지 담당
- 단일 또는 소수 서버 중심 운영
- 수동 배포 및 수동 장애 대응 방식에 가까움
→ 특정 시간대에 트래픽이 급증하는 구조를 가정하면 여러 문제가 발생한다
- 애플리케이션과 인프라 역할 강하게 결합
기존 구조 : FE, API Server, 백그라운드 작업, 세션 관리, 캐시, 큐 처리 등 한 구성요소의 부하가 다른 구성요소에 직접 영향
역할 분리가 충분 X) 특정 기능의 부하 = 전체 서비스 품질 저하
- 확장 단위가 비효율적
기존 구조 : 보통 서버 단위로 확장 실제로 모든 구성요소가 같은 비율로 부하 받지 않음
필요한 부분만 늘리는 것 X, 서버 전체를 늘려야 하는 비효율 발생
- 비동기 처리 분리가 부족할 시 순간 트래픽에 취약
기존 구조 : 순간적으로 요청이 몰리는 서비스 (ex) 수강신청, 래플, 선착순 이벤트, 대량 등록 처리 등) 모든 요청을 동기적으로 즉시 처리 → 병목 발생
burst traffic을 흡수하는 완충 지점(buffer) 부족
- 장애 격리 수준 낮음
기존 구조 : 적은 수의 서버에 여러 역할 → 특정 장애가 전체 서비스 영향
장애 국소화 X → 전체 장애로 확산
- 운영 자동화와 배포 일관성 부족
기존 구조 : 서버 접속 후 직접 배포 or 환경마다 수동으로 설정 맞춰야 함
유지보수 비용 증가
아키텍처 개선 방향
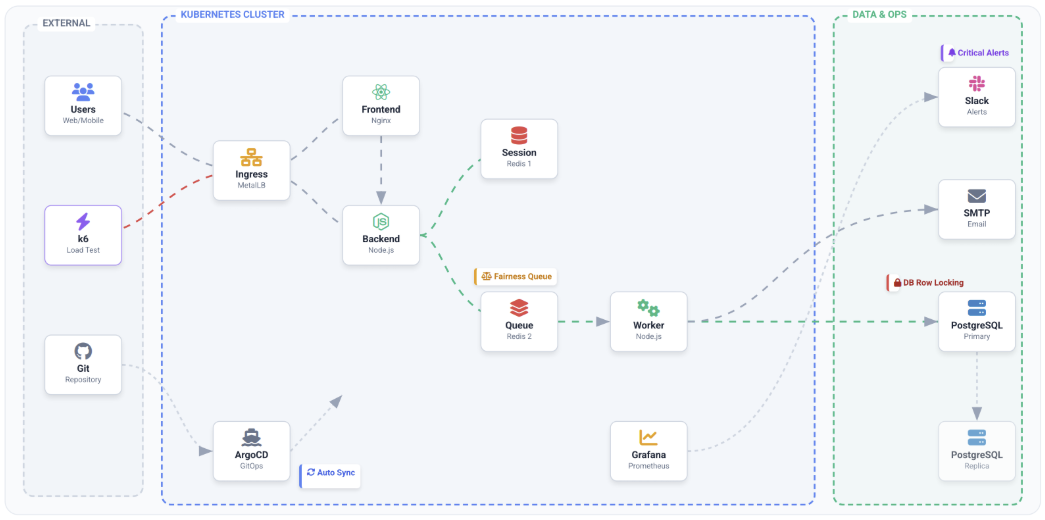
온프레미스 Kubernetes 기반의 분리형 서비스 아키텍처로 발전
- Kubernetes 기반으로 서비스 실행 환경 표준화
- FE / BE / Worker 역할 분리
- PostgreSQL 외부 분리
- Redis 역할 분리
- Redis Session
- Redis Queue
- DB / Redis에 Replica 구성
- Control Plane 이중화
- Ingress + MetalLB 기반 외부 진입 구조 정리
- ArgoCD 기반 GitOps 운영 구조 도입
- Prometheus + Grafana 모니터링 구조 도입
- Grafana Alert 기반 Slack 알람 기능 도입
즉, 단순한 3-Tier X
서비스 계층 분리 + 운영 자동화 + 확장성 + 장애 대응성
을 강화한 방향으로 발전
Kubernetes 도입
- 애플리케이션 실행 환경 표준화
- 프런트엔드, 백엔드, 워커를 각각 독립된 Deployment 로 관리
- 서비스별 실행 방식, 재시작 정책, 리소스 제한, 복제 개수 등 선언적 관리 가능
- YAML로 정의
- 운영 절차의 코드화
- 서비스별 독립 확장 가능
- 부하 특성에 따라 개별적으로 replicas 늘리기 가능
- 부하가 발생한 서비스만 선택적으로 확장
- 자가 복구 (Self-healing)
- 선언된 desired state를 유지하기 위해 자가 복구
- 기존 구조 → 장애 발생 후 사람이 복구
- Kubernetes 도입 후 → 시스템이 기본적으로 원하는 상태를 자동 유지
- 배포 일관성 & GitOps
- ArgoCD와 연계 → Git 저장소의 매니페스트 = 배포 기준
- 현재 운영 상태 Git 으로 추적 가능
- 변경 이력 관리 가능
- 동일한 방식으로 재현 가능
- 롤백 명확
- 배포를 수동 작업에서 형상관리 기반 운영으로 전환
DB를 Kubernetes 외부로 분리
- 상태 저장소와 애플리케이션 워크로드 분리
- 변화가 잦은 영역과 안정성이 중요한 영역 분리
-
운영 책임 분리와 관리 용이성
-
장애 영향 범위 축소
Redis - Session용과 Queue 용으로 분리
- 서로 다른 성격의 워크로드 분리
- Redis Session → 빠른 조회와 짧은 응답 시간
- Redis Queue → 처리량과 적체 관리
- 상호 간섭 방지
- 핵심 사용자 요청 경로와 백그라운드 처리 경로 분리
- 확장 및 튜닝 포인트 분리
- 운영 목적에 맞는 최적화를 가능하게 하는 구조적 선택
Replica 구성
- 서비스 가용성 향상
- 읽기 부하 분산 및 복구 기반 마련
해당 프로젝트의 replica 구성은
논리적/운영적 고가용성 구조를 학습하고 검증하는 목적
물리 장비 이중화의 HA와는 구분
Control Plane 2개 배치
- cp 구성 요소 분산
- 단일 cp 대비 관리 평면 이중화 방향성 확보
- kubeadm 기반 멀티 cp 구조
etcd quorum 관점 완전한 HA 구성 X
cp를 2개로 구성함으로 단일 마스터 구조보다 관리 평면 분산 구조
완전한 HA 제어 평면 관점 → quorum 확보를 위해 3개 이상의 cp 또는 별도 etcd 설계가 더 바람직
아키텍처 종합적 개선 효과
단일 서버 중심 구조 → 역할 분리 구조 수동 운영 중심 → 선언적 운영 구조
동기 처리 중심 → 비동기 처리 포함 구조
단일 장애 지점 많은 구조 → 분산 및 복제 구조
목적
단순 3-tier 구조에서 시작
실제 서비스 환경을 가정한 확장성과 안정성을 고려한 아키텍처로 점진적으로 발전시키는것
1. 기본 3-Tier 구조 설계
- 전통적인 Web / WAS / DB 구조를 기반으로 설계
- FE + BE 중심 구조
- 단일 DB 사용
- 동기 처리 중심 로직 구성
2. 역할 분리 및 비동기 처리 도입
- 트래픽 집중 상황을 고려하여 구조 개선 진행
- Backend와 Worker 분리
- Redis Queue 도입 (비동기 처리)
- 요청 처리와 작업 처리를 분리
burst traffic을 흡수할 수 있는 구조
API 응답 성능과 처리 안정성 개선
3. 상태 저장소 분리
- 애플리케이션과 데이터 계층 분리 진행
- PostgreSQL을 Kubernetes 외부로 분리
- Redis를 Session / Queue 용도로 분리
데이터 안정성 확보
역할별 리소스 간섭 최소화
운영 관리 포인트 명확화
4. Kubernetes 기반 실행 환경 전환
- 서비스 실행 환경을 Kubernetes 로 전환
- FE / BE / Worker를 각각 Deployment로 구성
- Service / Ingress 기반 네트워크 구조 정리
- MetalLB를 통한 온프레미스 LoadBalancer 구성
서비스 배포 표준화
확장 단위의 세분화
자가 복구 기반 확보
5. 가용성 및 확장성 강화
- Pod Replica 구성 (FE / BE / Worker)
- PostgreSQL / Redis replica 구성
- Control Plane 다중화
단일 장애 지점 감소
서비스 연속성 확보
확장 기반 마련
6. 운영 자동화 및 GitOps 도입
- ArgoCD를 통한 선언적 배포 관리
- Git 저장소를 단일 진실 소스로 활용
- 이미지 버전 기반 자동 배포 흐름 구성
배포 일관성 확보
변경 이력 추적 가능
운영 자동화 기반 구축
로드맵
1. 인프라 및 네트워크 기반 구축
목표
- 온프레미스 환경에서 네트워크 + 보안 + 접근 구조 포함 인프라 기반 구성
수행 내용
- VM 7대 구성
- Bastion Host 기반 접근 구조 설계
- 내부 네트워크 / 외부 접근 경로 분리
- GNS3 기반 네트워크 시뮬레이션
- 방화벽 정책 구성
- Gateway 이중화 구성
포인트
보안 구조까지 포함된 인프라
네트워크 레벨에서 단일 장애 지점 제거
2. Kubernetes 클러스터 구축 및 운영 기반 구성
목표
- 서비스 실행을 위한 Kubernetes 환경 구축
수행 내용
kubeadm기반 클러스터 구성Control Plane이중화Worker Node구성Calico CNI적용MetalLB/Ingress/metrics-server/storage구성
포인트
온프레미스에서 LoadBalancer 구현
Kubernetes 기반 서비스 실행 표준화
3. 모니터링 및 관측 환경 구축
목표
- 서비스 상태를 실시간으로 관측하고 장애 대응 체계 구축
수행 내용
- Prometheus / Grafana 구축
- 리소스 및 서비스 상태 시각화
- Alertmanager + Slack 연동
- 장애 알림 자동화
포인트
단순 모니터링 → 운영 대응까지 포함
보는것 → 알림 받는것까지 확장
4. 서비스 아키텍처 설계 및 데이터 계층 분리
목표
- 확장성과 안정성을 고려한 서비스 구조 설계
수행 내용
- Frontend / Backend / Worker 분리
- Redis Queue 기반 비동기 처리 도입
- Redis Session / Queue 분리
- PostgreSQL 외부 분리
- DB / Redis Replica 구성
포인트
동기 구조 → 비동기 구조 전환
단일 저장소 → 역할별 데이터 계층 분리
5. Kubernetes 기반 서비스 배포 및 고가용성 적용
목표
- 서비스를 Kubernetes 환경에서 안정적으로 운영
수행 내용
- Deployment / Service / Ingress 구성
- Pod Replica 적용
- Control Plane 이중화 유지
- 장애 상황 대응 테스트
포인트
서비스 실행 → 서비스 안정성 확보
Pod 단위 확장 및 복구
6. 운영 자동화 및 외부 접근 & 보안 확장
목표
- 운영 자동화 + 외부 접근 + 보안 + 검증 포함
수행 내용
- ArgoCD 기반 GitOps 구축
- Helm 기반 배포 구조
- cert-manager 기반 HTTPS 구성
- Cloudflare Tunnel 외부 노출
- 3-Tier vs 개선 아키텍처 비교 환경 구성
- Grafana 통합 대시보드 구성
포인트
수동 운영 → GitOps 자동화
내부 서비스 → 외부 접근 가능 서비스
단일 구조 → 비교 가능한 아키텍처
실제 동작 확인
서비스 접속 및 로그인
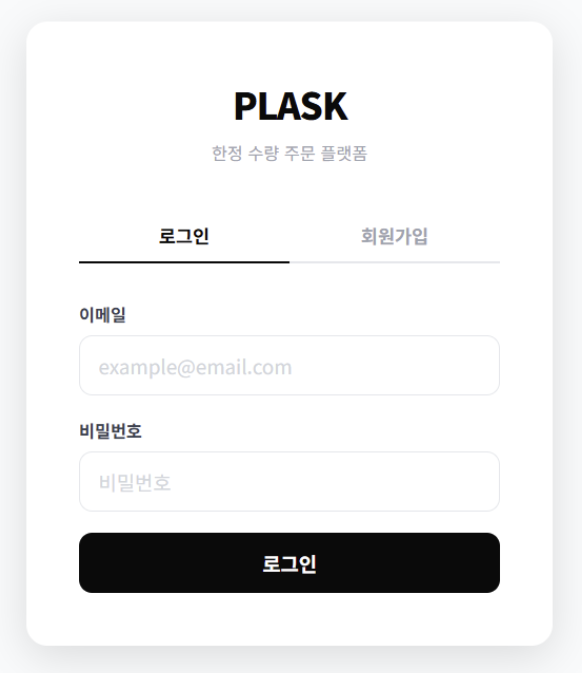
- 사용자는 등록된 이메일과 비밀번호를 입력하여 서비스에 접속한다.
- JWT(JSON Web Token) 기반의 인증 방식으로 보안이 강화된 세션을 생성한다.
- 로그인 성공 시 즉시 상품 목록 페이지로 리다이렉트한다.
상품 확인 및 오픈 카운트다운
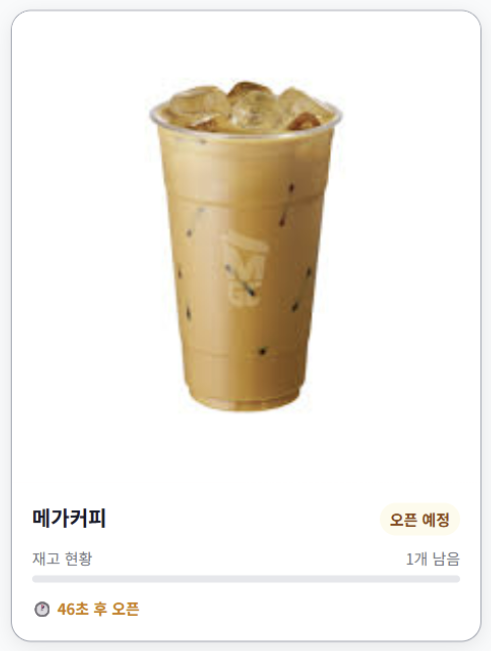
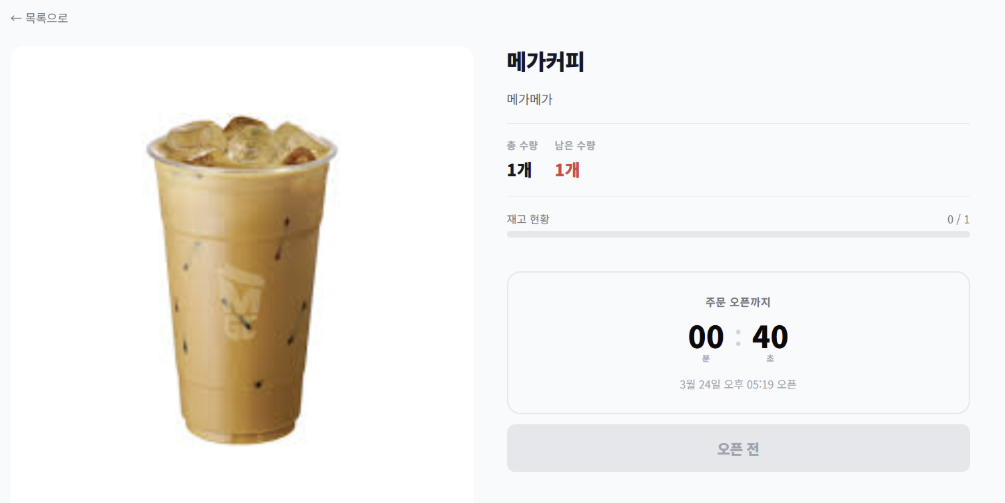
- 메인 상품 목록과 상세 페이지에서 판매 예정 상품의 재고 상태 및 판매 시작까지의 남은 시간을 실시간으로 확인한다.
- 정해진 오픈 시간 전까지 ‘지금 주문하기’ 버튼을 비활성화 상태로 유지한다.
선착순 주문 활성화 및 대기열 등록
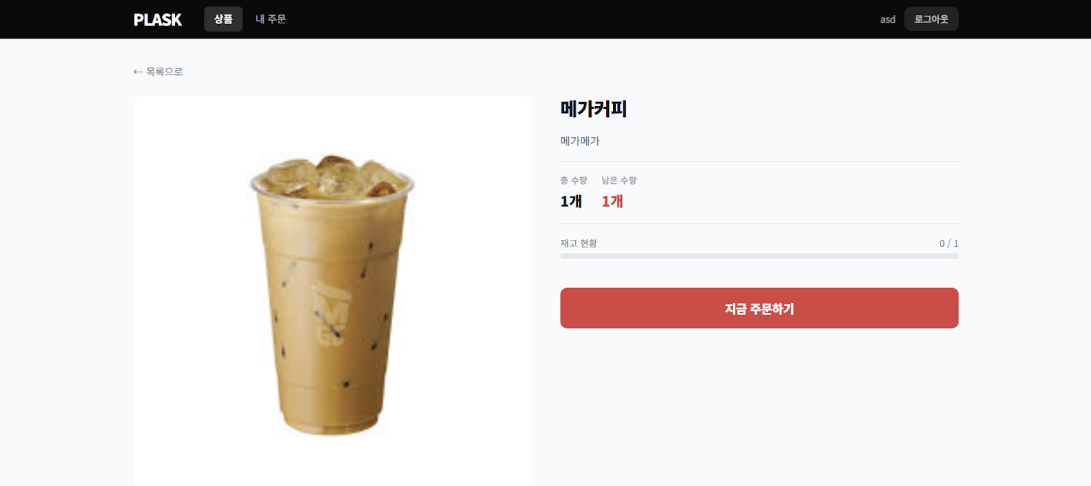
- 카운트다운이 종료됨과 동시에 ‘주문 하기’ 버튼이 활성화된다.
- 사용자가 버튼을 클릭하면 요청은 즉시 Redis 큐(FIFO)에 등록된다.
- 서버는 클라이언트 화면에 ‘주문 처리 중’ 오버레이를 표시하여 사용자에게 현재 비동기 처리가 진행 중임을 알린다.
주문 완료 처리 및 SMTP
- 백엔드의 워커(Worker)가 대기열 순서에 따라 재고를 차감하고 주문 데이터를 생성한다.
- 처리가 완료되면 화면에 주문 성공 모달이 나타나며, 이와 동시에 사용자의 이메일로 주문 완료 확인 메시지가 자동 발송된다.
실시간 재고 소진 및 품절 처리

- 설정된 한정 수량이 모두 소진될 경우, 상세 페이지의 버튼은 즉시 ‘품절’ 상태로 전환된다.
- 메인 목록의 상품 카드에도 ‘Sold Out’ 배지를 표시하여 추가적인 주문 진입을 차단한다.
주문 내역 검증
- 사용자는 ‘내 주문’ 메뉴를 통해 성공적으로 처리된 주문의 상세 정보와 결제 시간을 확인한다.
- 이를 통해 선착순 트래픽 폭주 상황에서도 데이터 정합성이 유지되었음을 검증한다.
프로젝트 핵심 성과 및 결론
기술 스택 통합 성과
- 인프라 : 단일 노트북 기반 VM 7대로 실운영 수준 인프라 재현
- 오케스트레이션 : Kubernetes HA 클러스터로 자동 복구 및 선언적 배포 환경 구축
- 아키텍처 설계 : 3-Tier → 비동기 Queue 기반 마이크로서비스 구조로 전환
- 데이터 계층 : 역할별 스토리지 분리 (PostgreSQL / Redis Session / Redis Queue)
- 네트워크/보안 : HSRP 이중화 + Router ACL + iptables 기반 다층 보안 구현
- 운영 자동화 : ArgoCD GitOps로 배포 시간 60~90% 단축
- 모니터링 : Prometheus + Grafana + Slack으로 장애 인지 시간 ~95% 단축
- 검증 : k6 부하 테스트: 100명 동시 접속, p95 394ms, HPA 2→5 자동 확장 검증
프로젝트의 기술적 의미
본 프로젝트는 단순한 기술 스택 교체가 아닌, 아키텍처 사고 방식의 전환을 보여주는 사례이다. 기존의 단일 서버, 동기 처리, 수동 운영 패러다임에서 분산 컨테이너, 비동기 처리, 자동화 운영 패러다임으로의 전환이 실제 성능 수치로 검증되었다. 특히 온프레미스 환경에서 클라우드 수준의 탄력성과 자동화를 구현하였다는 점에서 의미가 크다. MetalLB와 Ingress NGINX를 통해 클라우드 로드 밸런서를 대체하고, ArgoCD와 Helm으로 클라우드 관리형 CI/CD를 대체함으로써, 클라우드 비용 없이도 클라우드 수준의 운영 성숙도를 달성하였다.
운영 관점에서의 의미
아키텍처의 가치는 구축 시점이 아니라 운영 중 발생하는 예상치 못한 상황에서 드러난다. 본 프로젝트에서 구축된 아키텍처는 다음과 같은 운영 상황에서 자동으로 대응할 수 있다.
- 트래픽 급증 : HPA가 Pod를 자동 확장하여 응답 시간 유지
- Pod 장애 : Kubernetes가 자동으로 Pod를 재스케줄링하여 서비스 연속성 유지
- 배포 오류 : ArgoCD를 통한 이전 버전 즉시 롤백
- 성능 저하 : Alertmanager가 Slack으로 자동 알림, 즉시 인지 및 대응
- 보안 접근 시도 : Bastion 감사 로그를 통한 이상 접근 탐지
이러한 자동화 수준은 소수의 운영 인력으로도 프로덕션 수준의 서비스를 안정적으로 운영할 수 있는 기반을 제공한다.
향후 개선 방향
본 프로젝트에서 구축한 아키텍처를 기반으로 다음과 같은 방향의 추가 개선이 가능하다.
| 개선 영역 | 내용 | 기대 효과 |
|---|---|---|
| Control Plane | 2대에서 3대로 증설 | etcd 쿼럼 강화, HA 완전성 향상 |
| Worker 확장 | Worker 전용 HPA 튜닝 | DB 부하 탄력적 조절 |
| Redis HA | Redis Sentinel 또는 Cluster 도입 | Redis 단일 장애 제거 |
| 서비스 메시 | Istio / Linkerd 도입 검토 | 서비스 간 mTLS, 세밀한 트래픽 제어 |
| 테스트 자동화 | k6 CI 파이프라인 통합 | 배포 전 성능 회귀 자동 감지 |
| 로그 수집 | Loki + Grafana 연동 | 메트릭과 로그의 통합 관찰성 |
정량적 성과 요약
| 측정 항목 | Before | After | 개선율 |
|---|---|---|---|
| API 응답 시간 | 기준 | 80.4% 감소 | 80.4% |
| Backend CPU 사용률 | 기준 | 70% 감소 | 70% |
| 장애 인지 시간 | 수 분 이상 | 수 초 이내 | ~95% |
| 배포 시간 | 30분 이상 | 5분 이내 | 80~90% |
| k6 p95 응답 시간 | 미측정 | 394ms | 목표 대비 ↓ 80% |
전체 통합 아키텍처
프로젝트 총평
Team Plask
온프레미스 Kubernetes 클러스터 위에 비동기 Queue 기반 서비스 아키텍처를 구현하고, GitOps CI/CD, 자동 스케일링, 실시간 모니터링을 통합 운영하는 체계를 성공적으로 구축하였다.
부하 테스트를 통해 p95 응답시간 394ms, 성공률 99.8%, Pod 자동확장(2→5) 등 목표 지표를 모두 달성하였으며,
응답 시간 5067% 감소, CPU 사용률 2040% 감소, 배포 시간 80% 단축의 정량적 개선을 검증하였다.