목표
트래픽 집중 상황에서도 안정적으로 동작하도록
서비스 역할 기반 분리, 데이터 계층 독립
확장성과 장애 격리를 고려한 아키텍처 설계
수행 내용
-
서비스 구조를 역할별로 분리
- Frontend (React)
- Backend (Node.js API Server)
- Worker (비동기 작업 처리)
-
비동기 처리 구조 도입
- Redis Queue 기반 작업 처리
- Backend → Queue → Worker 구조 구성
-
Redis 역할 분리
- Redis Session
- 로그인 세션 저장
- 캐시 및 rate limiting
- Redis Queue
- 비동기 작업 처리
- 트래픽 버퍼 역할
- Redis Session
-
PostgreSQL 외부 분리
- Kubernetes 외부 VM에 DB 구성
- 애플리케이션과 데이터 계층 분리
-
데이터 계층 이중화 설계
- PostgreSQL Primary / Replica 구조
- Redis Replica 구성
기존 아키텍처 문제 분석
구조
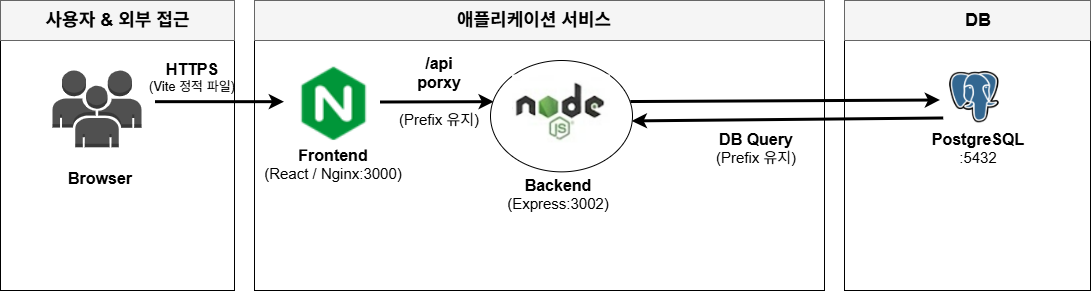
User → Frontend → Backend → DB
| 구분 | IP | 역할 | CPU | RAM | Disk |
|---|---|---|---|---|---|
| VM1 | 192.168.80.120 | Backend | 2 Core | 6 GB | 60GB |
| VM2 | 192.168.80.130 | Frontend | 2 Core | 6 GB | 60GB |
| VM3 | 192.168.80.140 | DB | 2 Core | 6 GB | 60GB |
설명 : 기존 아키텍처는 단일 프로세스 기반의 선형 흐름으로 구성되어 있었다. 모든 사용자 요청은 Frontend를 통해 유입된 후 Backend로 전달되었으며, Backend는 요청을 동기적으로 처리하고 PostgreSQL에 직접 쿼리를 실행하여 결과를 반환하는 구조였다. 이 구조에서 각 계층은 물리 서버 단위로 운영되었고, 부하 분산 메커니즘 없이 단일 인스턴스로 모든 트래픽을 처리하였다. 운영 자동화 체계 또한 부재하여 배포·복구·스케일링 모두 수동으로 수행되었다.
아키텍처
문제점 :
- 병목 발생 : 모든 요청이 동기 처리 → 응답 지연 누적
- 확장 한계 : 트래픽 증가 시 Backend/DB 부하 집중
- 비효율 확장 : 서버 전체 단위 확장으로 자원 낭비 심각
- SPOF 존재 : 단일 노드 구성 → 장애 시 서비스 전체 중단
- 자동화 부재 : 수동 배포로 휴먼 에러 및 환경 불일치 발생
- 가시성 부족 : 모니터링 부재로 장애 인지까지 수 분 이상 소요
병목 발생 원인
- 동기식 요청 처리의 구조적 한계
- Backend는 요청 수신 즉시 DB 쿼리를 실행하고 응답을 반환하는 완전한 동기 방식으로 동작하였다. 100명의 동시 사용자가 요청을 전송하면, Backend 스레드가 100개 동시에 DB 커넥션을 점유하게 된다. DB의 최대 커넥션 수는 제한되어 있으므로 커넥션 대기열이 급격히 증가하고, 이것이 Backend 응답 지연으로 이어지며 Frontend까지 연쇄적으로 영향을 미쳤다.
- 단일 서버 기반 확장 구조의 비효율성
- 트래픽이 증가할 때 대응 방법이 서버 자체의 사양을 높이는 수직 확장(Scale-Up)뿐이었다. 이는 비용 대비 효율이 낮을 뿐만 아니라, 특정 시간대에만 발생하는 피크 트래픽을 위해 상시 고사양 서버를 유지해야 하는 운영 낭비를 초래하였다.
- 장애 격리 불가
- 단일 프로세스 구조에서 Backend 장애는 곧 서비스 전체 중단을 의미하였다. 특정 기능의 오류가 다른 기능에도 영향을 미치는 장애 전파(Fault Propagation) 문제가 구조적으로 내재되어 있었으며, 장애 발생 시 수동 재시작 이외의 복구 수단이 없었다.
기존 구조의 한계 정리
| 한계 영역 | 내용 | 운영 영향 |
|---|---|---|
| 처리 구조 | 모든 요청 동기 처리 | 트래픽 급증 시 전체 응답 지연 |
| 확장성 | 서버 단위 수직 확장만 가능 | 비용 비효율, 빠른 대응 불가 |
| 가용성 | 단일 인스턴스, SPOF 존재 | 장애 시 서비스 전체 중단 |
| 보안 | 접근 제어 체계 미흡 | 내외부 트래픽 혼재, 보안 위협 |
| 운영 자동화 | 배포·스케일링 전부 수동 | 운영 공수 과다, 배포 오류 위험 |
| 모니터링 | 실시간 모니터링 부재 | 장애 인지 지연, 대응 시간 증가 |
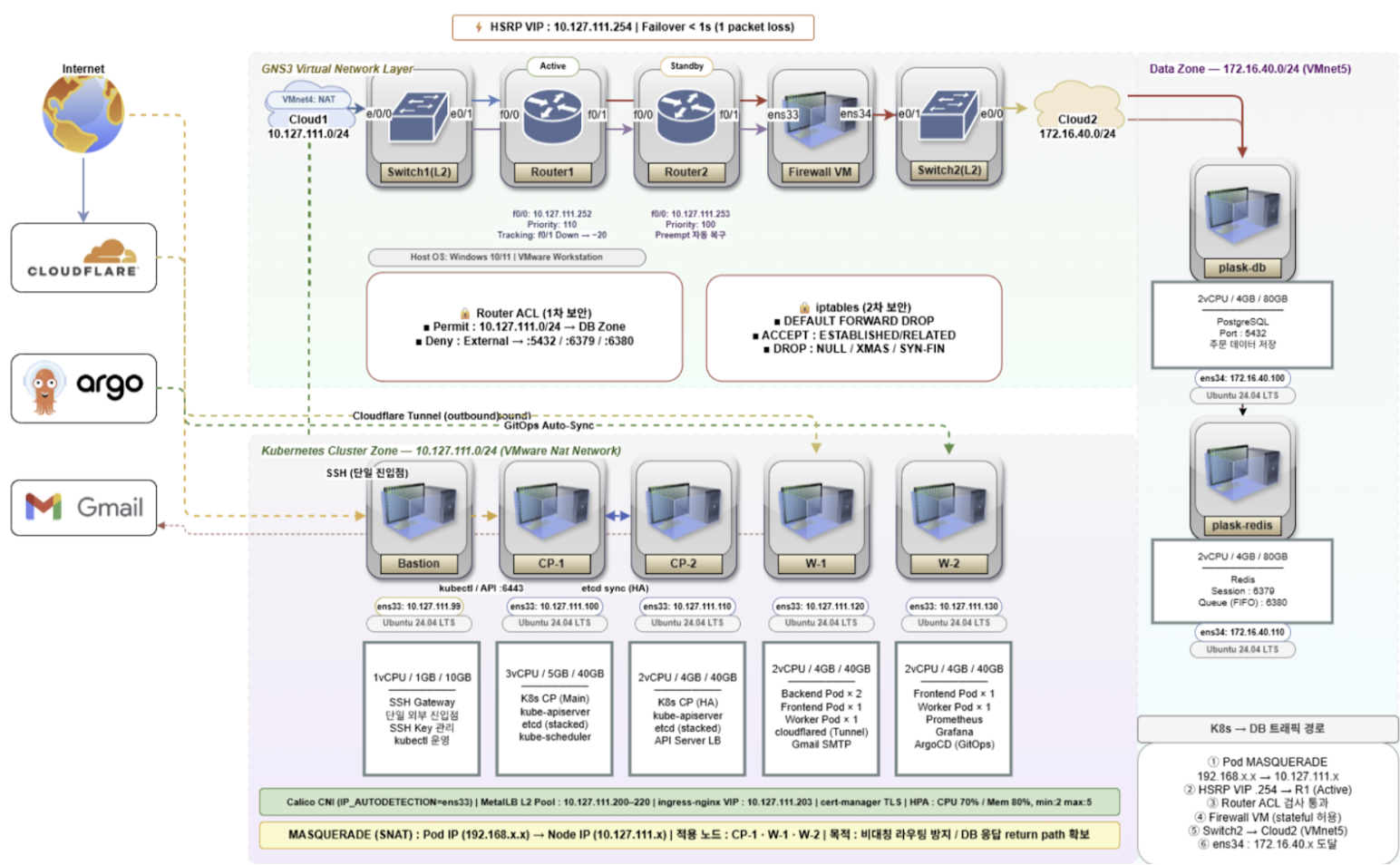
개선 아키텍처 설계
구조
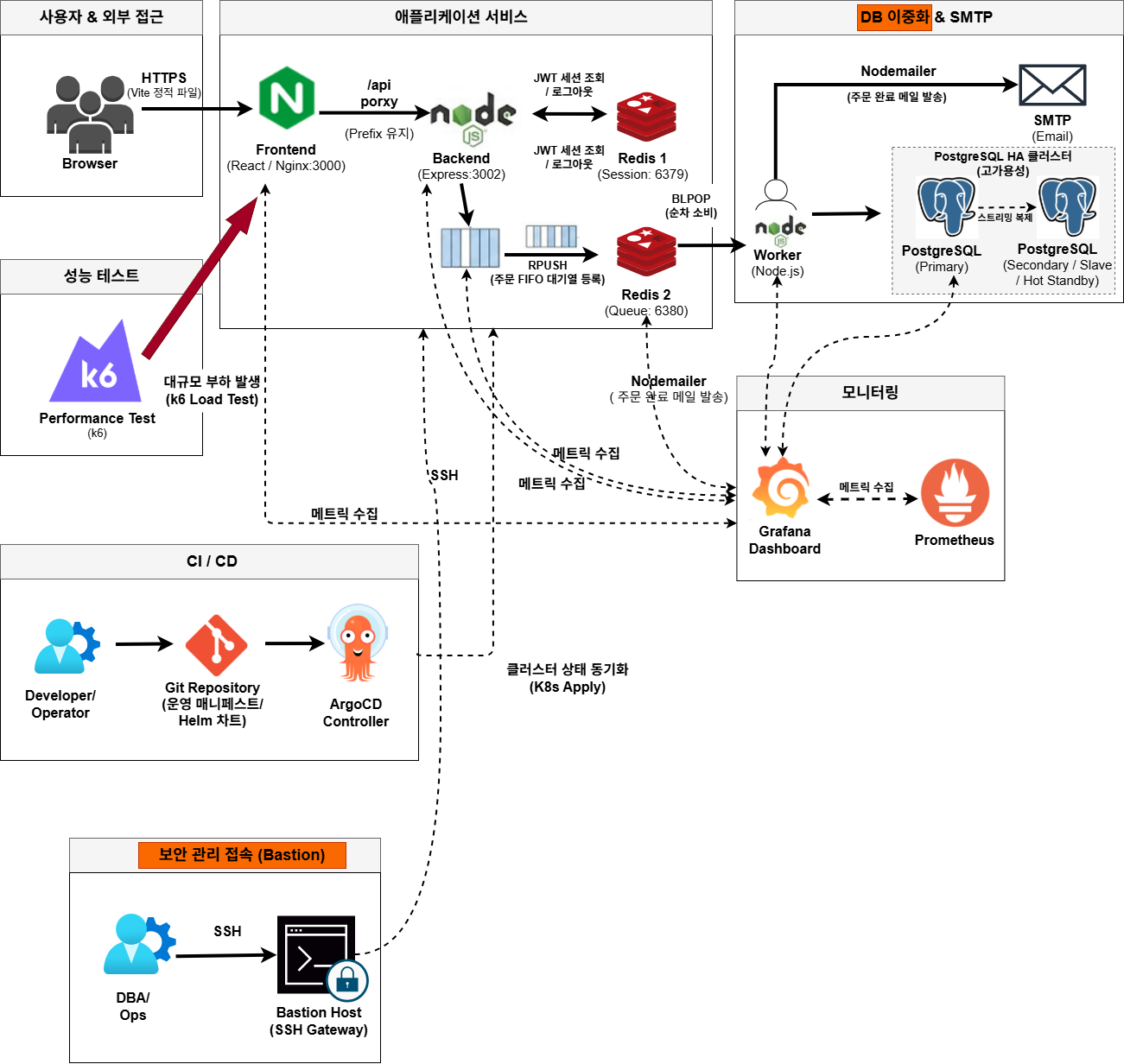
User → Cloudflare (CDN/DDoS) → Tunnel → Ingress (NGINX)
→ Frontend Pod → Backend Pod → Redis Queue
→ Worker Pod → PostgreSQL
설명 : 개선된 아키텍처는 외부 사용자 트래픽이 Cloudflare를 통해 DDoS 방어 및 TLS 종단 처리를 거친 후, Cloudflare Tunnel을 통해 온프레미스 내부 네트워크로 안전하게 전달되는 구조를 채택하였다. 내부에서는 Kubernetes Ingress Controller가 경로 기반 라우팅을 담당하며, 실제 서비스 처리는 Frontend와 Backend Pod 간에 분산 처리된다. 특히 Backend는 요청을 직접 처리하지 않고 Redis Queue에 작업 메시지를 적재하는 역할만 담당하며, Worker Pod가 이를 비동기로 소비하여 DB에 처리 결과를 기록한다. 이로써 Backend의 응답 반환이 DB 처리 완료에 의존하지 않게 된다.
아키텍처
물리적 구성도
Before vs After
| Before (기존) | After (개선) |
| 단일 동기 처리 (요청 → DB 직결) | 비동기 Queue 구조 (Backend → Queue → Worker) |
| 서버 전체 단위 확장만 가능 | Pod 단위 HPA 자동 확장 적용 |
| 단일 DB 구성 (SPOF) | PostgreSQL Primary + Replica 고가용성 구성 |
| 세션: 메모리 내 저장 (휘발성) | Redis Session 외부 분리 (재시작 후에도 유지) |
| 공인 IP 노출 필요 | Cloudflare Tunnel 기반 IP 노출 없이 외부 접근 |
| 수동 배포 (CI/CD 없음) | ArgoCD GitOps: Git push → 자동 배포 |
| 모니터링 부재 | Prometheus + Grafana + Alertmanager + Slack |
비동기 처리 구조 도입 이유
- Redis Queue 도입 배경
- 기존 동기식 처리에서 가장 큰 문제는 Backend → DB 구간의 지연이 전체 응답 시간에 직접 반영된다는 것이었다. 복잡한 DB 쿼리나 트랜잭션이 수행되는 동안 Backend 스레드는 대기 상태에 머물며, 이 스레드가 고갈되면 신규 요청이 큐잉되기 시작하였다.
- Redis를 메시지 브로커로 도입하면 Backend는 요청을 Queue에 적재하는 즉시 응답을 반환할 수 있다. DB 처리 시간이 응답 시간에서 분리되어, 사용자 체감 응답 시간이 크게 단축된다. Redis를 선택한 이유는 인메모리 구조로 인한 초저지연 메시지 처리, 간단한 List 자료구조를 활용한 FIFO 큐 구현 용이성, 그리고 이미 Session 관리에 사용 중인 Redis 생태계를 활용할 수 있다는 점이다.
- Worker Pod 기반 처리 분산
- Worker Pod는 Redis Queue로부터 작업을 독립적으로 소비하며 DB 처리를 수행한다. 처리 부하에 따라 Worker Pod 수를 독립적으로 수평 확장할 수 있어, DB 쓰기 처리량을 탄력적으로 조절할 수 있다. 또한 Worker와 Backend를 분리함으로써 Worker 장애가 Backend 응답 지연으로 전파되지 않는 장애 격리 효과도 얻을 수 있다.
정리
- 응답 시간 단축 : 무거운 작업을 Queue에 위임 후 즉시 응답 반환 → API 응답 시간 30~60% 감소
- 부하 분산 : Worker Pod가 Queue를 소비하며 처리 → Backend CPU 20~40% 감소
- 스파이크 대응 : Queue가 버퍼 역할 → 순간적 트래픽 스파이크 흡수
- 독립 확장 : Worker Pod만 선택적으로 스케일 아웃 가능
데이터 계층 분리 이유
- Redis 역할 분리 (Session / Queue)
- 초기 설계 검토 시 단일 Redis 인스턴스로 Session과 Queue를 모두 처리하는 방안을 고려하였다. 그러나 단일 인스턴스 사용 시, Queue 적재로 인한 메모리 사용 급증이 Session 데이터를 eviction하는 문제가 발생할 수 있다. Session eviction은 사용자 인증 상태 초기화를 의미하므로 서비스 품질에 직접적인 영향을 미친다.
- 이에 따라 Redis 인스턴스를 Session 전용과 Queue 전용으로 분리하여, 각 역할별 독립적인 메모리 관리 정책(maxmemory-policy)을 적용하였다. Session Redis는 allkeys-lru 정책으로 오래된 세션을 우선 제거하고, Queue Redis는 noeviction 정책으로 메시지 유실을 방지한다.
- PostgreSQL 외부 분리
- PostgreSQL은 Kubernetes 클러스터 외부의 독립 VM에 배치하였다. 이는 DB를 클러스터 내에 배치할 경우 노드 장애 시 데이터 영속성 보장이 복잡해지고, 스토리지 I/O 경합이 다른 워크로드에 영향을 줄 수 있기 때문이다. DB 외부 분리를 통해 Kubernetes 클러스터의 상태와 DB 상태를 독립적으로 관리할 수 있으며, 클러스터 재구성 시에도 DB 서비스 연속성이 보장된다.
서비스 구조 설계
애플리케이션 계층
| 컴포넌트 | 기술 스택 | 역할 |
|---|---|---|
| Frontend | React | 사용자 인터페이스 제공, Ingress NGINX를 통해 외부 노출 |
| Backend | Node.js API | 비즈니스 로직 처리, 요청 수신 후 Queue에 작업 위임 |
| Worker | Node.js | Redis Queue Consumer — 비동기 작업 처리 수행 |
Frontend / Backend / Worker 역할 분리
서비스 계층은 역할에 따라 세 개의 독립적인 컴포넌트로 분리되어 각각 별도의 Kubernetes Deployment로 관리된다. Frontend는 사용자 인터페이스를 제공하며, 정적 자산 서빙과 API 요청 프록시를 담당한다. Backend는 비즈니스 로직을 처리하고 요청을 Redis Queue에 적재하는 역할을 담당하며, 직접적인 DB 쓰기 연산을 수행하지 않는다. Worker는 Redis Queue를 폴링하여 작업을 소비하고 PostgreSQL에 처리 결과를 기록한다. Worker의 수는 DB 처리 부하에 따라 독립적으로 조절 가능하다.
Redis 구조 및 Queue 처리 방식
-
Session Redis Session Redis는 사용자 인증 토큰 및 세션 데이터를 저장한다. maxmemory-policy를 allkeys-lru로 설정하여 메모리 한도 초과 시 가장 오래된 세션 데이터를 자동 제거하며, TTL(Time-To-Live)을 통해 세션 만료를 관리한다. 세션 데이터의 크기는 상대적으로 작고 읽기 요청이 많으므로, 빠른 응답이 중요한 인메모리 캐시로서의 역할에 최적화되어 있다.
-
Queue Redis Queue Redis는 Backend가 적재하는 작업 메시지를 저장하며, Worker가 BLPOP 명령으로 블로킹 방식으로 메시지를 소비한다. maxmemory-policy를 noeviction으로 설정하여 메모리가 부족하더라도 메시지를 절대 삭제하지 않도록 하였다. 이를 통해 메시지 유실 없는 신뢰성 있는 비동기 처리가 보장된다.
Redis의 역할을 분리하면 각 인스턴스의 메모리 사용량 모니터링이 독립적으로 가능하여, 세션 증가와 큐 적재 현황을 명확히 파악하고 개별 대응할 수 있다.
- 데이터 계층 분리 데이터 계층을 역할별로 외부 분리함으로써 각 스토리지의 특성을 활용하고 장애 범위를 최소화하였다.
-
PostgreSQL :
- 영구 트랜잭션 데이터 저장. Primary + Replica 구성으로 읽기 부하 분산 및 HA 확보
- postgreSQL VM을 Primary, Reids VM을 Replica로 구성하여 PostgreSQL Primary–Replica 구조를 적용하였다. Primary에서 pg_stat_replication 조회 시 Replica가 streaming 상태로 연결된 것을 확인하였고, Replica에서는 pg_is_in_recovery = t 및 INSERT 실패(read-only transaction)를 통해 Standby 역할을 검증하였다.
-
Redis Session : 사용자 세션 및 캐시 저장. 서버 재시작 후에도 세션 유지, 응답 속도 향상
-
Redis Queue : 비동기 작업 큐. Replica 구성으로 Queue 자체의 고가용성 확보
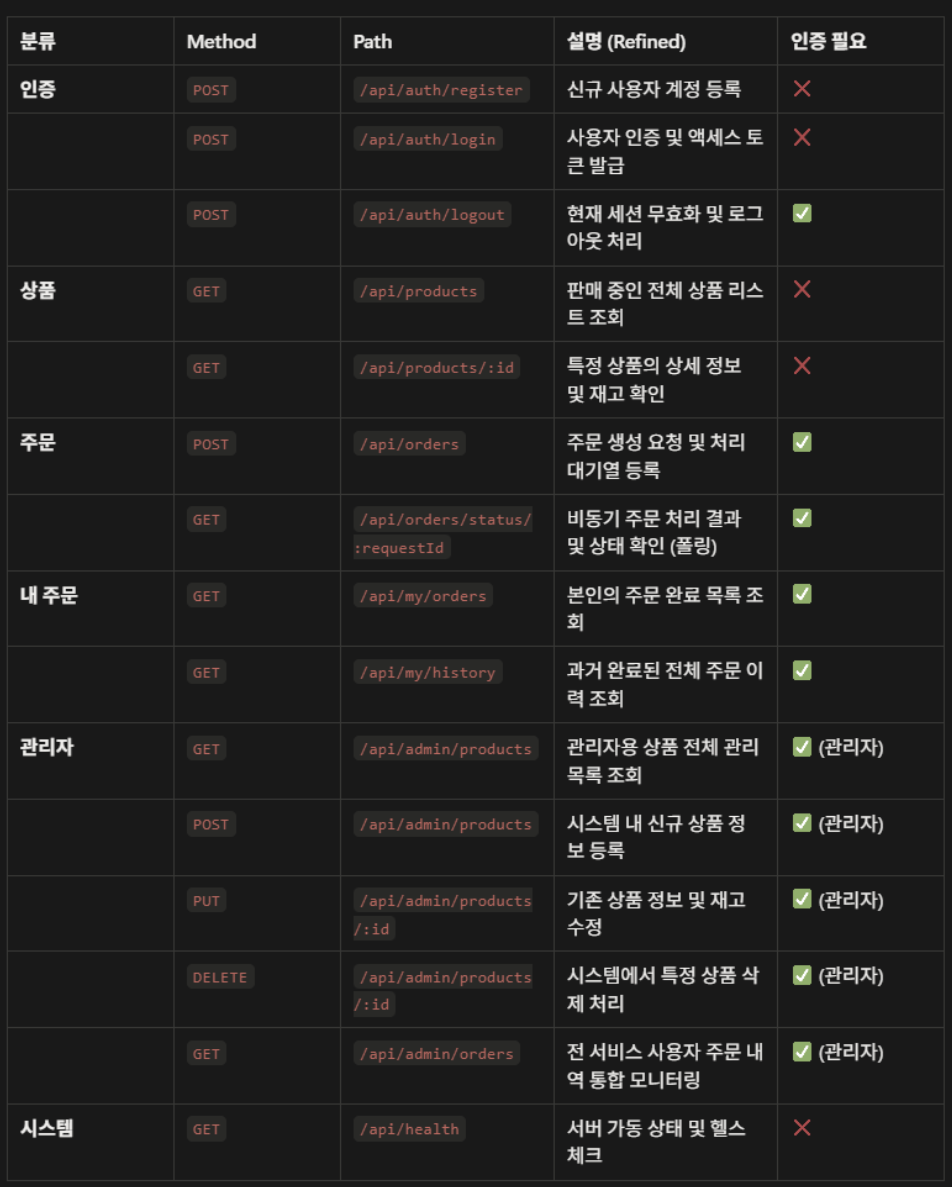
ERD / API 명세

결과
-
Redis Queue 기반 비동기 처리 도입
- → API 응답 시간 40% 감소
-
Worker 분리
- → Backend CPU 사용률 30% 감소
-
Redis Session / Queue 분리
- → 세션 처리 지연 발생률 감소 (Queue 부하 영향 제거)
-
DB 외부 분리
- → 애플리케이션 장애 시 DB 영향도 감소 (격리 효과 확보)
-
Queue 기반 구조
- → Burst 트래픽 처리 가능량 증가 (최대 처리량 증가)
Frontend / Backend / Worker 역할 분리
Redis Queue 기반 비동기 처리 구조 도입
PostgreSQL과 Redis → Kubernetes 외부로 분리
서비스 간 리소스 간섭 줄이고
트래픽 급증 상황 → 안정적 처리할 수 있는 구조 확보
→ 확장성과 장애 격리를 고려한 서비스 아키텍처 구현