Controller = 원하는 상태(Desired State)를 실제 상태(Current State)와 일치 자동조정기
Kubernetes 리소스 계층 구조
Deployment (선언)
↓ 생성/관리
ReplicaSet (복제 관리)
↓ 생성/관리
Pod (실행 단위)
↓
Container (실행 프로세스)
-
사용자는 Deployment 만 직접 관리
-
ReplicaSet은 대부분 직접 생성 X
-
Pod은 Deployment 에 의해 생성
-
Pod
- 가장 작은 실행 단위
- 하나 이상의 컨테이너 포함
- 직접 운영용으로 사용 X
- 삭제되면 사라짐 (관리 객체 필요)
-
ReplicaSet
- 지정된 수의 Pod을 항상 유지
- Self-healing (자동 복구)
- 라벨 기반 Pod 관리
- 스케일링 가능
- 업그레이드 기능 X
-
Deployment
- ReplicaSet을 관리하면서 배포 전략 제공
- Rolling Update
- Rollback
- 버전 관리
- 업그레이드 일시 중지
- 자동 ReplicaSet 생성
Controller 동작 원리
kubectl apply실행- API Server가 요청 검증, etcd 저장
- Controller가 API Server 를 Watch
- Desired State와 Current State 비교
- 차이가 있다면 수정 작업 수행
- 계속 감시 (Watch)
- 상태 비교 (Reconcile)
- 수정 (Action)
- → Reconciliation Loop
while(true) {
현재상태 = API 조회
원하는상태 = Spec 확인
차이점 계산
수정 실행
}
Controller 종류
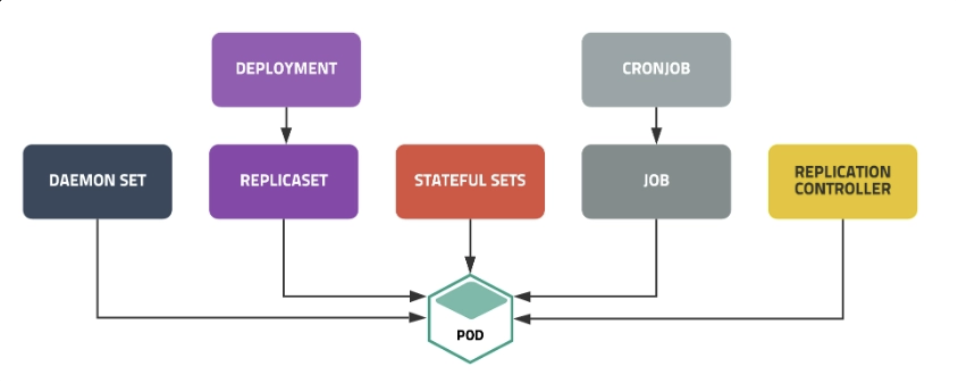
-
ReplicationController
- 지정한 개수의 Pod를 유지하는 가장 초기 Controller
- ReplicaSet 의 구버전
- 역할 : 항상 N개의 Pod 유지
-
ReplicaSet Controller
- 역할 : 지정한 개수만큼 Pod 유지 ex)
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
- Pod 삭제 시 (
kubectl delete pod <pod이름>)- 자동으로 새 Pod 생성 → ReplicaSet Controller 감지
- Deployment Controller
- ReplicaSet을 관리하는 상위 Controller
- 역할
- ReplicaSet 생성
- Rolling Update 관리
- 롤백 지원 ex)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.25
- 이미지 버전 변경 시 (
kubectl set image deployment nginx-deploy nginx=nginx:1.26)- 새로운 ReplicaSet 생성
- 기존 ReplicaSet 점진적으로 감소
- Rolling Update 수행
-
StatefulSet Controller
- 역할
- Pod 이름 고정
- 순차적 생성/삭제
- 영구 스토리지 연결
- ex) DB, Kafka, Redis 같은 Stateful 앱에서 사용
- 역할
-
DaemonSet Controller
- 역할 : 모든 노드에 Pod 하나씩 배포
- ex) 로그 수집기, 모니터링 에이전트, CNI 플러그인 ex)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- name: node-exporter
image: prom/node-exporter
- 노드 추가시 자동으로 Pod 생성
-
Job Controller
- 역할 : 한 번 실행하고 종료되는 작업 관리
- ex) 배치 처리, DB 마이그레이션
-
CronJob Controller
- 역할 : 스케줄 기반 실행
- Linux cron 과 유사
ReplicaSet
1. desired replicas 확인
2. 현재 Pod 수 확인
3. 부족하면 생성
4. 초과하면 삭제
5. Pod 죽으면 다시 생성
- ReplicaSet은 Pod 개수만 관리
ex)
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
-
selector.matchLabels = template.metadata.labels- 반드시 동일해야 함
- 불일치 시 Pod 관리 X / ReplicaSet이 계속 새 Pod 생성
-
한계점
- 이미지 변경 시 → 기존 Pod 유지 / 새 Pod만 변경
ReplicaSet은 무중단 업그레이드 보장 X
Deployment
새 ReplicaSet 생성
→ 기존 ReplicaSet 점진적 축소
→ 새 ReplicaSet 점진적 증가
- Deployment는 ReplicaSet을 교체하는 전략 관리자
ex)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
revisionHistoryLimit: 5 # 이전 버전 보관 개수
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
-
revisionHistoryLimit
- 이전 ReplicaSet을 몇 개까지 보관할지 지정
- default : 10
-
Rolling Update
- 하나씩 교체
- 무중단
-
Recreate
- 기존 Pod 모두 삭제
- 새 Pod 생성
- 다운타임 발생
- → DB 처럼 단일 인스턴스 환경에서 사용
-
히스토리 확인 :
kubectl rollout history deployment/nginx-deployment -
특정 버전 롤백 :
kubectl rollout undo deployment/nginx-deployment --to-revision=1- Deployment 는 내부적으로 이전 ReplicaSet을 다시 활성화
-
트러블슈팅
- Pod가 Pending 상태인 경우 :
kubectl describe pod <pod>- Node 리소스 부족
- taints 문제
- 이미지 pull 실패
- 롤아웃이 멈춘 경우
kubectl rollout status deployment/<name> kubectl describe deployment <name> kubectl get events- CrashLoopBackOff
kubectl logs <pod> kubectl logs <pod> --previous - Pod가 Pending 상태인 경우 :
StatefulSet
-
상태를 가진 애플리케이션 (Stateful Application) 관리 Kubernetes 리소스
-
각 Pod 고유한 정체성 (identity) 가지며 순서대로 배포, 삭제
-
Deployment와 차이점
- Pod 이름 고정
- Pod 마다 독립적인 스토리지
- 생성 및 삭제 순서 보장
-
특징
-
안정적인 네트워크 ID
- Pod 이름 고정
- Pod이 재시작되어도 동일한 이름과 DNS 유지
- Headless Service 반드시 필요,
clusterIP: None설정 있어야 Pod 개별 DNS 생성
- Pod 이름 고정
-
순차적 배포 및 삭제
- 생성 순서 :
mysql-0 → mysql-1 → mysql-2 - 삭제 순서 :
mysql-2 → mysql-1 → mysql-0 - 앞 Pod이 Ready 상태 되기 전 다음 Pod 생성 X
- 기본값
podManagementPolicy: OrderedReady때문 - 필요시
Parallel로 변경 가능
- 생성 순서 :
-
Persistent Volume (PV) 연결
- 각 Pod 독립적인 저장소 가짐
- Pod 재시작 후 같은 PVC 연결
- 운영 시
volumeClaimTemplates사용 emptyDir은 임시 저장소 → DB 사용 X
-
Headless Service 필요
- StatefulSet 는 반드시 Headless Service와 함께 사용
clusterIP: None: 설정 X → Pod DNS 생성 X
-
-
예시
- 데이터베이스 (MySQL, PostgreSQL, MongoDB)
- 메시지 큐 (Kafka, RabbitMQ)
- 분산 시스템 (Cassandra, ElasticSearch)
-
순서 중요
-
고정 hostname 필요
-
데이터 영속성 필요
ex)
apiVersion: v1
kind: Service
metadata:
name: mysql-headless
spec:
clusterIP: None # Headless Service
selector:
app: mysql
ports:
- port: 3306
targetPort: 3306
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: mysql-headless # StatefulSet과 연결할 Service
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "password123"
volumeMounts:
- name: mysql-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-storage
emptyDir: {} # 임시 저장소, pod 삭제 시 데이터도 삭제됨
- Service 부분
clusterIP: None→ Headless Service 설정selector→ StatefulSet Pod과 연결port→ Service 포트targetPort→ Pod 내부 포트
- StatefulSet 부분
serviceName→ Headless Service 이름과 반드시 일치replicas→ 생성할 Pod 수selector.matchLabels관리 대상 Pod 라벨template.metadata.labels→ 반드시 selector와 동일containers.image→ 컨테이너 이미지env→ 환경변수 설정volumeMounts→ Pod 내부 경로에 볼륨 연결volumes.emptyDir→ 임시 저장소
emptyDir: {}: 이 경우 Pod 삭제 시 데이터 삭제 / StatefulSet의 장점 X- → 변경 필요
volumeClaimTemplates: - metadata: name: mysql-storage spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 1Gi
DaemonSet
-
모든 노드(또는 특정 노드)에 1개씩 Pod을 실행
-
replicas 지정 X
-
노드 수 = Pod 수
-
특징
-
모든 노드에서 실행
- 새로운 노드 추가 → 자동으로 Pod 배포
- 노드 제거 시 Pod 삭제
- 노드당 정확히 1개 Pod 생성
-
상태 비저장
- Pod 간 순서 X
- 고유 ID X
- 재시작 가능
-
노드 선택 가능
- nodeSelector
- affinity
- tolerations
- 특정 조건에 맞는 노드에만 배포 가능
-
-
예시
- 로그 수집기 (Fluentd)
- 모니터링 에이전트 (Node Exporter)
- 네트워크 플러그인
- 특정노드 → GPU 노드 전용 작업
ex)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-logger
namespace: default
spec:
selector:
matchLabels:
app: node-logger
template:
metadata:
labels:
app: node-logger
spec:
containers:
- name: logger
image: busybox:latest
command: ["sh", "-c"]
args:
- |
while true; do
echo "Running on node: $(hostname)"
sleep 10
done
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 50m
memory: 64Mi
selector.matchLabels→ 관리 대상 Pod 선택template.metadata.labels→ 반드시 동일command→ ENTRYPOINT overrideargs→ CMD overrideresources.requests→ 스케줄 기준resources.limits→ 최대 사용 자원updateStrategy→ 기본값 :RollingUpdate- 옵션
updateStrategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1
Job
-
일회성 작업을 실행하기 위한 Kubernetes 리소스
- Deployment → 계속 실행
-
예시
- 데이터 마이그레이션
- 배치 처리
- 백업 작업
- 초기화 스크립트
- 대량 데이터 처리
Job 생성
↓
Pod 생성
↓
작업 수행
↓
성공(Exit 0)
↓
Job Completed
-
실패 시 설정 조건에 따라 재시도
-
특징
- 완료 조건 지정 가능
- 병렬 실행 가능
- 실패 시 재시도 가능
- 완료 후 리소스 자동 삭제 가능
ex)
apiVersion: batch/v1
kind: Job
metadata:
name: hello-job
spec:
completions: 1
parallelism: 1
backoffLimit: 4
activeDeadlineSeconds: 100
ttlSecondsAfterFinished: 30
template:
metadata:
labels:
app: hello-job
spec:
restartPolicy: OnFailure
containers:
- name: hello
image: busybox:latest
command: ["sh", "-c"]
args:
- echo "Hello Kubernetes Job"; sleep 5
-
옵션
-
completions: ex)completions: 1- 성공해야 할 총 작업 수
- 1이면 한 번 성공 시 완료
-
parallelism: ex)parallelism: 1- 동시에 실행할 Pod 수
- completions과 함께 동작
completions: 5 parallelism: 2-
동시 2개 실행 / 총 5번 성공 시 완료
-
backoffLimit: ex)backoffLimit: 4- 실패 시 재시도 횟수
- 초과하면 Job은 Failed 상태
-
activeDeadlineSeconds: ex)activeDeadlineSeconds: 100- Job 전체 실행 최대 시간
- 초과 시 강제 종료
-
ttlSecondsAfterFinished: ex)ttlSecondsAfterFinished: 30- 완료 후 자동 삭제 시간
- 클러스터 리소스 정리 목적
-
-
주의 사항
- restartPilicy는 Never 또는 OnFailure 만 가능
- 병렬 실행 시 외부 자원 충돌 가능
- ttlSecondsAfterFinished 설정 권장
CronJob
- 정기적으로 Job을 실행하는 리소스
- Linux cron과 동일한 스케줄 문법 사용
- 직접 Pod 생성 X → 내부적으로 Job 생성
CronJob
↓
(스케줄 도달)
↓
Job 생성
↓
Pod 실행
- 특징
- 주기적 실행
- 동시 실행 제어 가능
- 성공/실패 Job 보관 개수 설정 가능
- 일시 중지 가능
ex)
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello-cron
spec:
schedule: "*/1 * * * *"
concurrencyPolicy: Allow
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
suspend: false
jobTemplate:
spec:
backoffLimit: 3
template:
spec:
restartPolicy: OnFailure
containers:
- name: hello
image: busybox
command: ["sh", "-c"]
args:
- echo "Hello from CronJob"; date
- 옵션
-
schedule: ex)"*/1 * * * *"- 형식 :
분 시 일 월 요일
- 형식 :
-
concurrencyPolicy
-
| 값 | 의미 |
|---|---|
| Allow | 동시에 실행 허용 |
| Forbid | 이전 Job 완료 후 실행 |
| Replace | 기존 Job 종료 후 새 Job 실행 |
- 보통 Forbid 또는 Replace 사용
- `successfulJobsHistoryLimit` : 성공한 Job 보관 개수
- `failedJobsHistoryLimit` : 실패한 Job 보관 개수
- `suspend` : ex) `suspend: true`
- true → 실행 중지
- false → 정상 실행
- `jobTemplate`
- CronJob이 생성할 Job 정의
- Job spec과 동일 구조
- 주의사항
- schedule 오타 매우 흔함
- 클러스터 시간대 기준 실행
- concurrencyPolicy 설정 필수
- 장시간 작업은 겹치지 않도록 설계
ReplicaSet
- Pod 개수 유지
- 자동 복구
- 업그레이드 전략 X
Deployment
- ReplicaSet 관리
- 무중단 배포
- 롤백 가능
- 프로덕션 기본 단위
Deployment 생성
↓
ReplicaSet 자동 생성
↓
Pod 생성
↓
Container 실행
StatefulSet
- 순서가 중요한 애플리케이션
- 고유한 네트워크 ID 필요
- 데이터 영속성 필요
- Pod 간 역할 구분 필요
DaemonSet
- 모든 노드에서 실행 필요
- 노드별 1개 Pod 필요
- 상태 비저장 작업
- 노드 추가 시 자동 확장 필요
| 항목 | StatefulSet | DaemonSet |
|---|---|---|
| 목적 | 상태 있는 앱 관리 | 모든 노드 실행 |
| Pod 개수 | replicas 수 | 노드 수 |
| Pod 정체성 | 고정 | 노드마다 자동 |
| 배포 순서 | 순차 | 동시 |
| 네트워크 ID | 안정적 DNS | 변할 수 있음 |
| 스토리지 | PersistentVolume 필요 | 보통 필요 없음 |
| 사용 사례 | DB, 메시지큐 | 로깅, 모니터링 |
| 스케일링 | 수동 (replicas) | 노드 추가 시 자동 |
Job
- 일회성 작업
- 병렬 실행 가능
- 재시도 설정 가능
CronJob
- 주기적 실행
- 내부적으로 Job 생성
- 동시 실행 정책 중요
| 항목 | Job | CronJob |
|---|---|---|
| 실행 방식 | 1회 실행 | 주기적 실행 |
| 스케줄 | 없음 | cron 표현식 |
| 내부 구조 | Pod 실행 | Job 생성 |
| 동시 실행 제어 | 없음 | concurrencyPolicy |